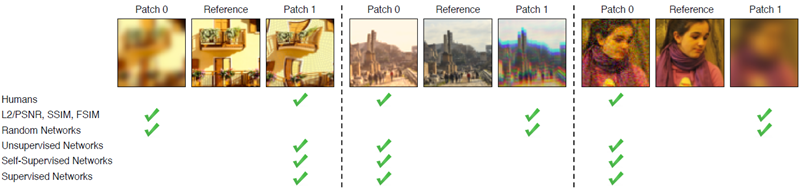
図1:これらの例において、どちらのパッチ(左または右)が中央のパッチに「近い」だろうか?いずれの場合も、従来の指標(L2/PSNR、SSIM、FSIM)は人間の判断と一致しない。しかし、深層ネットワークは、アーキテクチャ(Squeezenet [18]、AlexNet [25]、VGG [48])や教師あり学習(教師あり学習 [44]、自己教師あり学習 [12、37、40、59]、さらには教師なし学習 [24])を問わず、人間の判断と驚くほどよく一致する創発的な埋め込みを提供する。我々は、既存の深層埋め込みを、知覚判断の大規模データベースでさらにキャリブレーションした。モデルとデータはhttps://www.github.com/richzhang/PerceptualSimilarityで見ることができる。
人間が 2 つの画像の知覚的類似性を素早く評価するのにほとんど努力は要らないが、その根底にあるプロセスは非常に複雑だと考えられている。それにもかかわらず、PSNR や SSIM など、今日最も広く使用されている知覚指標は単純で浅い関数であり、人間の知覚の多くのニュアンスを考慮できていない。最近、ディープラーニング コミュニティは、ImageNet 分類タスクでトレーニングされた VGG ネットワークの特徴が、画像合成のトレーニング損失として非常に有用であることを発見した。しかし、これらのいわゆる「知覚損失」はどの程度知覚的なものだろうか?それらの成功にはどのような要素が重要なのだろうか?これらの質問に答えるために、我々は知覚的な人間の判断に関する新しい Full Reference Image Quality Assessment (FR-IQA) データセットを導入する。これは以前のデータセットよりも桁違いに大きい。異なるアーキテクチャとタスクにわたって深層特徴を体系的に評価し、それらを従来の指標と比較する。その結果、深層特徴はこれまでのすべての指標を大幅に上回ることがわかった。さらに驚くべきことに、この結果はImageNetで学習されたVGG特徴量に限定されるものではなく、様々な深層学習アーキテクチャや教師あり学習、自己教師あり学習、さらには教師なし学習にも当てはまる。我々の研究結果は、知覚的類似性が深層学習における視覚表現全体に共通する創発的な特性であることを示唆している。
データ項目を比較する能力は、おそらくすべてのコンピューティングの基礎となる最も基本的な操作である。コンピュータサイエンスの多くの分野では、これはそれほど難しいことではない。ハミング距離を使用してバイナリパターンを比較したり、編集距離を使用してテキストファイルを比較したり、ユークリッド距離を使用してベクトルを比較したりすることができる。コンピュータビジョンに特有の課題は、視覚パターンを比較するという一見単純なタスクでさえ、未解決の問題が残っていることである。視覚パターンは非常に高次元で相関性が高いだけでなく、視覚的な類似性という概念自体が主観的であることが多く、人間の視覚知覚を模倣することを目的としている。たとえば、画像圧縮では、ピクセル表現が大きく異なる可能性があるという事実に関係なく、圧縮された画像が人間の観察者にとって元の画像と区別がつかないようにすることが目標である。
回帰問題で一般的に用いられる \(l^2\) ユークリッド距離や、関連するピーク信号対雑音比 (PSNR) といった、ピクセル単位の古典的な指標は、画像などの構造化された出力を評価するには不十分である。なぜなら、これらの指標は、入力が与えられた場合、各出力ピクセルが他のすべてのピクセルから条件付きで独立していると仮定しているからである。よく知られた例としては、画像をぼかすと、知覚的には大きな変化が生じるが、ユークリッド的な変化は小さい。
我々が本当に求めているのは、「知覚距離」、つまり人間の判断と一致する方法で2つの画像がどの程度類似しているかを測定することである。この問題は、しばしばフルリファレンス画像品質評価(FR-IQA)と呼ばれ、コミュニティにおける長年の目標であり、SSIM [53]、MSSIM [55]、FSIM [57]、HDR-VDP [32]など、知覚に基づいた距離指標が数多く提案されてきた。
しかし、知覚的測定基準を構築することは困難である。なぜなら、人間の類似性の判断は (1) 高次の画像構造に依存する [53]、(2) 文脈に依存する [17, 34, 33]、(3) 実際には距離測定基準を構成しない可能性がある [51] ためである。 (2) の核心は、赤い円は赤い四角形と似ているのだろうか、それとも青い円と似ているのであろうか?人間の判断に関数を直接当てはめることは、判断が文脈に依存し、2 つの画像間の類似性を比較する性質があるため、困難な場合がある。実際、本論文では、これまでに利用可能だったものよりも数桁大きいデータセットでトレーニングした場合でも、このアプローチが一般化できないという否定的な結果を示している。
代わりに、知覚的類似性の概念を直接訓練することなく学習する方法があるのではないだろうか?コンピュータービジョンコミュニティは、高レベルの画像分類タスクで訓練された深層畳み込みネットワークの内部活性度が、はるかに幅広いタスクの表現空間として驚くほど有用であることを発見した。例えば、VGGアーキテクチャ[48]の特徴は、ニューラルスタイル転移[16]、画像超解像[21]、条件付き画像合成[13, 8]などのタスクに利用されている。これらの手法は、画像回帰問題における「知覚的」損失として、VGG特徴空間における距離を測定する[21, 13]。
しかし、これらの「知覚的損失」は実際に人間の視覚とどの程度一致するのであろうか?従来の知覚的画像評価指標と比べるとどうであろうか?ネットワークアーキテクチャは重要だろうか?ImageNet分類タスクでトレーニングする必要があるのだろうか?それとも、他のタスクでも同様に機能するのだろうか?そもそもネットワークをトレーニングする必要があるのだろうか?
本稿では、これらの疑問を人間の判断に関する新たな大規模データベースを用いて評価し、いくつかの驚くべき結論に至った。高レベル分類タスク向けに訓練されたネットワークの内部活性度は、追加のキャリブレーションなしでも、ネットワークアーキテクチャ[18, 26, 48]を横断しても、人間の知覚判断と実によく一致し、SSIMやFSIM[53, 57]といった一般的に用いられる指標よりもはるかに優れていることがわかった。さらに、Bi-GAN[12]、クロスチャネル予測[59]、パズル解決[37]といった、最も優れた自己教師ありネットワークは、人間がラベル付けした訓練データを用いなくても、このタスクにおいて同等の性能を発揮した。積み重ねられたk平均法[24]を用いた単純な教師なしネットワーク初期化でさえ、従来の指標を大幅に上回った。これは、ネットワーク全体、さらにはアーキテクチャや訓練信号にも共通する、新たな特性を示している。しかしながら、重要なのは、何らかの訓練信号を用いることが不可欠であるということである。ランダムに初期化されたネットワークは、はるかに低い性能しか達成しない。
本研究は、新たに収集された484,000件の人間の判断を含むFR-IQAデータセットに基づいている。従来のデータセットとは異なり、本研究の判断は、多数の歪みと実際のアルゴリズム出力に基づいて収集されており、コントラストや彩度の調整、ノイズパターン、フィルタリング、空間ワーピング操作などの従来の歪みと、オートエンコード、ノイズ除去、カラー化など、様々なアーキテクチャや損失によって生成されるCNNベースのアルゴリズム出力の両方が含まれている。本データセットは、この種の以前のデータセット[42]よりも桁違いに豊富で多様である。また、超解像、フレーム補間、画像ぼかし除去などのタスクにおける実際のアルゴリズムの出力に関する判断も収集している。これは、知覚指標の実際の使用例であるため、特に重要である。本データを使用して、レイヤーの活性化の単純な線形スケーリングを学習することにより、既存のネットワークを「キャリブレーション」し、低レベルの人間の判断により適合させることができることを示す。
我々の結果は、知覚的類似性はそれ自体が特別な機能ではなく、むしろ世界の重要な構造を予測するように調整された視覚表現の結果であるという仮説と整合している。意味予測課題において効果的な表現は、ユークリッド距離が知覚的類似性の判断を高度に予測する表現でもある。
我々の貢献は以下の通り:

表1:データセットの比較。提案するBerkeley-Adobe Perceptual Patch Similarity(BAPPS)データセットと先行研究の主な違いは、画像数と歪み数の両方における規模にある。非圧縮画像[7, 9]の画像を用いて、歪みセットに対する人間の知覚判断を提供する。先行データセットは少数の歪みを離散レベルで使用していたが、我々は多数の歪み(不可分歪(?atomic distortions)を連続的に合成することで作成)を使用し、連続的にサンプリングする。各入力パッチに対して、2つの歪みを用いてそれを改ざんし、ペアごとに少数の人間の判断(トレーニングセットの場合は2つ、テストセットの場合は5つ)を求める。これにより、多数のパッチに対する判断を得ることができる。先行データベースは、判断を平均オピニオンスコア(MOS)に要約するが、我々はペアごとの判断(2つの二者択一の力の選択)を単純に報告する。さらに、実際のアルゴリズムの出力に対する判断、および同一/非同一Just
FR-IQAデータセットに関する先行研究 既存の類似度指標を評価するために、多くのFR-IQAデータセットが提案されている。最も人気のあるデータセットとしては、LIVE [47]、TID2008 [43]、CSIQ [27]、TID2013 [42] などがある。これらは、FR-IQA類似度指標の開発と評価における事実上のベースラインとして機能してきた。我々は、これらを補完する新しいデータセットを収集する。このデータセットには、より新しいディープニューラルネットワークベースの出力を含む、はるかに多くの歪みが含まれている。さらに、このデータセットは、フル画像ではなくパッチ画像、野外、異なる実験設計で収集されている(詳細は第2章を参照)。
IQA のためのディープ ネットワークに関する先行研究
最近、DNN の進歩により、画像品質評価のコンテキストでのアプリケーションの調査が促進されている。Kim と Lee [23] は、CNN を使用して、低レベルの違いをトレーニングすることで視覚的な類似性を予測している。Talebi と Milanfar [50] による同時研究では、画像の美観を目的とした参照なしの IQA のコンテキストでディープ ネットワークをトレーニングしている。Gao ら [15] と Amirshahi ら [3] は、ディープ ネットワーク (それぞれ VGG と AlexNet) の内部活性度と追加のマルチスケール後処理を活用する手法を提案している。本研究では、新しい大規模で非常に多様なデータセットに対して、さまざまなアーキテクチャ、トレーニング信号にわたるより詳細な研究を行った。
最近、Berardinoら[6]はFRIQAを用いてネットワークを学習させ、特に重要な点として、深層ネットワークが別のタスク(知覚的に最も顕著な歪みの方向と最も顕著でない方向の予測)において予測を行う能力を評価した。本研究では、パラメータ化された歪みに対するFR-IQAの評価だけでなく、実際のアルゴリズムへの一般化、そして別の知覚タスク(知覚可能な差異のみ)への一般化も検証した。
異なる知覚指標の性能を評価するため、2つのアプローチを用いて、大規模かつ多様な知覚判断データセットを収集した。主なデータ収集では、2つの歪みのうちどちらが参照画像に類似しているかを問う2択強制選択(2AFC)テストを採用した。これは、連続する2枚の画像が同じか異なるかを問う、弁別閾(JND)テストを実行する2つ目の実験によって検証される。これらの判断は、広範囲にわたる歪みと実際のアルゴリズム出力から収集された。
まず、2AFC データセットに使用される従来の歪みと CNN ベースの歪みを定義する。
従来の歪み
入力パッチに対して実行される一般的な操作で構成される「従来の」歪みのセットを作成する(表2(左)を参照)。一般的には、測光歪み、ランダムノイズ、ぼかし、空間シフトと破損、圧縮アーティファクトを使用する。図2に、従来の歪みの定性的な例を示す。各摂動の強度はパラメーター化されている。例えば、ガウスぼかしの場合、カーネル幅によって入力画像に適用される破損の量が決まる。また、歪みのペアを順次合成することで、歪みの可能な空間全体を拡大する。合計で、20種類の歪みと、順次合成された308種類の歪みがある。
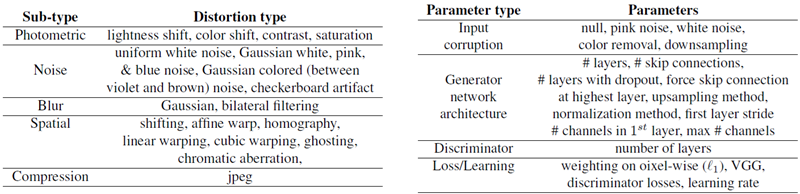
表2:我々の歪み。従来の歪み(左)は、基本的な低レベルの画像編集操作によって実行される。また、空間をより適切に探索するために、それらを順次合成している。CNNベースの歪み(右)は、タスク、ネットワークアーキテクチャ、学習パラメータなどのパラメータをランダムに変化させることによって形成される。これらの歪みの目的は、実際のアルゴリズムの出力に見られるような、ありそうな歪みを模倣することである。

CNNベースの歪み
ディープラーニングベースの手法から発生する可能性のあるアーティファクトの空間をより綿密にシミュレートするために、ニューラルネットワークによって作成される高レベルの歪みのセットを作成する。表2(右)に示すように、さまざまなタスク、アーキテクチャ、損失を探索することにより、考えられるアルゴリズムの出力をシミュレートする。このようなタスクには、オートエンコード、ノイズ除去、カラー化、超解像度が含まれる。これらのタスクはすべて、入力に適切な破損を適用することで実現できる。合計で96個の「オートエンコーダ」を生成し、CNNベースの歪み関数として使用する。これらの各ネットワークを1.3MのImageNetデータセット[44]で1エポックトレーニングする。各ネットワークの目標は、タスク自体を解決することではなく、ディープラーニングベースの方法の出力に悩まされる一般的なアーティファクトを探索することである。
実際のアルゴリズムによる歪んだ画像パッチ 画像評価アルゴリズムの真のテストは、実際の問題と実際のアルゴリズムを用いて行われる。我々は、このような出力を用いて知覚的判断を収集する。実際のアルゴリズムに関するデータは、それぞれのアプリケーションが独自の特性を持つため、より限られている。例えば、異なるカラー化手法は構造的な変化をあまり示さないが、色のにじみや色のばらつきといった影響を受けやすくなる。一方、超解像では色の曖昧さは発生しないが、アルゴリズムごとに構造的な変化が大きく見られる場合がある。
超解像
2017年のNTIREワークショップ[2]の結果を評価する。ワークショップの3つのトラック(×2、×3、×4のアップサンプリングレートと「不明」なダウンサンプリングレート)を用いて入力画像を作成する。各トラックには約20のアルゴリズムが提出されていた。また、バイキュービックアップサンプリングや、上位4つの深層超解像手法[22、54、29、45]を含むいくつかの追加手法も評価する。超解像の結果を定性的に提示する一般的な方法は、特定のパッチを拡大して差異を比較することである。そこで、Div2K [2]データセット(真の高解像度画像)の画像のランダムな場所からランダムに64×64のトリプレットをサンプリングし、2つのアルゴリズムの出力と併せて評価する。
フレーム補間
Davis Middleburryデータセット[46]において、フローベース補間[31]、CNNベース補間[36]、位相ベース補間[35]の3種類の異なるフレーム補間アルゴリズムを用いてパッチをサンプリングする。フレーム補間によって生じるアーティファクトは異なるスケールで発生する可能性があるため、パッチトリプレットをサンプリングする前に画像をランダムに再スケーリングする。
ビデオのぼかし除去
ビデオのぼかし除去データセット[49]からサンプリングしたデータに加え、Photoshop Shake Reduction、Weighted Fourier Aggregation[10]、および3種類の深層ビデオぼかし除去手法[49]からのぼかし除去出力も使用した。
カラー化
ImageNetデータセット[44]の画像に対し、カラー化タスクにおいてランダムスケールを用いてパッチをサンプリングする。アルゴリズムはpix2pix [20]、Larsson et al. [28]、およびZhang et al. [58]の派生アルゴリズムを用いた。
2AFC類似性判定
画像パッチ \(x\) をランダムに選択し、2つの歪みを適用して歪んだパッチ \(x_0,x_1\)を生成する。次に、どちらのパッチが元の画像パッチ \(x\) に近いかを人間に尋ね、その回答 \(h\) を記録する。平均して、人間は1回の判定につき約3秒を費やした。パッチトリプレット\((x,x_0,x_1,h)\) のIQAデータセットを \(\mathcal T\) とする。
我々のデータセットと以前のデータセットの比較を表1に示す。以前のデータセットは、少数の画像と歪みの種類に対する人間の判断を大量に収集することに焦点を当てていた。たとえば、最大のデータセットTID2013 [42]には、3000の歪みに対する50万の判断が含まれている(25の入力画像と24の歪みの種類があり、それぞれ5レベルでサンプリングされている)。我々は、代わりに多数の歪みの種類と多数の画像に焦点を当てた補完的なデータセットを提供する。さらに、完全な画像ではなく、小さな64×64パッチで判断を収集することを選択した。これには3つの理由がある。まず、完全な画像の空間は非常に大きく、判断でドメインの妥当な部分をカバーするのがはるかに難しくなる(64×64のカラーパッチでさえ、扱いにくい12k次元の空間を表す)。第二に、パッチサイズを小さくすることで、類似性の低レベルな側面に焦点を当て、高レベルな意味論[34]の影響を受ける可能性のある「類似性の程度」の差異の影響を軽減する。最後に、画像合成の最新手法では、パッチベースの損失(畳み込みとして実装)を用いて深層ネットワークを学習する[8, 19]。本データセットは、学習用にMIT-Adobe 5kデータセット[7](非圧縮画像5000枚)と検証用にRAISE1kデータセット[9]から得られた161,000以上のパッチで構成されている。
大規模な収集を可能にするため、データは管理された実験室環境ではなく、Amazon Mechanical Turk 上で「in-the-wild (実世界)」で収集された。これにより、現実世界のディスプレイデバイスと視聴条件の分布全体にわたってデータを収集することが可能になり、これは知覚メトリクスの現実世界でのユースケースにとって重要である。「訓練」セットでは例ごとに2つの判断を求め、「検証」セットでは5つの判断を求める。判断の数を減らすことで、より多くの画像パッチと歪みのセットを探索できる。明らかな変形を持つパッチのペア(例えば、大量のガウスノイズと少量のガウスノイズなど)で構成されるセンチネル(監視者)を追加する。Turk 参加者の約90%が、センチネルの少なくとも93%(15個中14個)を正しく合格できた。これは、参加者がタスクを理解し、注意を払っていたことを示している。以前のデータセットよりも多くの歪みを使用することで、FR-IQA メトリクスの可能性のあるユースケース空間をより広くサンプリングできる。
弁別閾(JND:Just noticeable differences 辛うじて気づくことができる差異)
2AFCタスクの潜在的な欠点は、参加者がタスクを完了するためにどの類似点に焦点を当てるかを意識的に選択できるという意味で「認知的に浸透可能」であることであり[34]、これは判断に主観を導入する。判断が実際に客観的で意味のある何かを反映していることを確認するために、「弁別閾」(JND)のユーザー判断も収集した。参照画像を示し、その後にランダムに歪んだ画像を示し、人間に画像が同じか異なるかを尋ねる。2つの画像パッチは、250ミリ秒の間隔を空けて、それぞれ1秒間表示される。似ている2つの画像は簡単に混同される場合があり、優れた知覚測定基準を使用すれば、最も混同しやすいものから最も混同しにくいものの順にペアを順序付けることができる。このようなJNDテストは、各判断に対して1つの正解があり、参加者は正しい行動に必要なことを認識していると推定されるため、主観性が低いと見なされる。従来型およびCNNベースの検証セットに含まれる4,800個のパッチそれぞれについて、3つのJND観測値を収集した。各被験者には、160組のパッチと40個のセンチネル(同一が32個、大きなガウスノイズ歪みが適用された8個)が表示される。また、同じパッチが4組、明らかに異なるパッチが1組、そして歪みによって生成された異なるパッチが5組含まれる10枚の画像による短期トレーニング期間も提供する。これは、パッチペアの約40%が同一であるとユーザーに期待させるためである。実際、36.4%のパッチペアが「同一」とマークされた(センチネルペアの70.4%、テストペアの27.9%)。
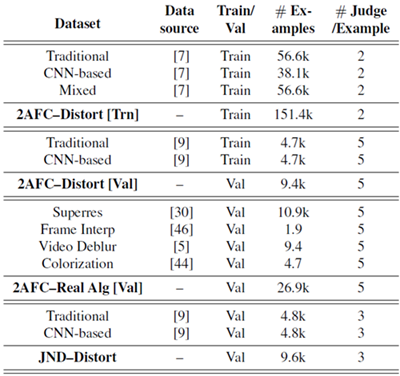
表3:データセットの内訳。2AFCデータセットを3つの主要な部分に分割した。(1,2) 歪みを含むトレーニングセットとテストセット。トレーニングセットとテストセットには、それぞれMIT5k [7] とRAISE1k [9] データセットからサンプリングしたパッチが含まれている。(3) 実際のアルゴリズム出力を含むテストセット。様々なアプリケーションからのパッチが含まれている。JNDデータは、従来の歪みとCNNベースの歪みに基づいている。
異なるネットワークにおける特徴距離を評価する。与えられた畳み込み層について、コサイン距離(チャネル次元)とネットワークの空間次元および層間の平均を計算する。また、既存のネットワークをデータに合わせて調整する方法についても説明する。
ネットワークアーキテクチャ SqueezeNet [18]、AlexNet [26]、および VGG [48] アーキテクチャを評価する。VGG ネットワークは、画像生成タスクの事実上の標準となっている [16, 13, 8]。ニューラルスタイル転移 [16] でよく使用される 5 つの conv レイヤー (conv1 2 層、conv2 2 層、conv3 3 層、conv4 3 層、conv5 3 層) を使用する。また、人間の視覚皮質のアーキテクチャにより適合する可能性のある、より浅い AlexNet ネットワークとも比較する。[25] の conv1-conv5 レイヤーを使用する。最後に、SqueezeNet アーキテクチャは、AlexNet と同様の分類性能を備え、サイズが非常に軽量 (2.8 MB) になるように設計されている。最初の conv レイヤーと後続の「fire」モジュールを使用する。
さらに、パズル解決[37]、クロスチャネル予測[59]、カラー化[58]、ビデオ学習[40]、生成モデリング[12]など、いくつかの自己教師あり学習手法を評価した。これらの手法と、AlexNet [26]の派生型を用いた他の自己教師あり学習手法から得られた公開ネットワークを用いた。
ネットワーク活性度から距離を計算する 図 3 (左) は、ネットワーク \(\mathcal F\) を使用して、参照パッチと歪んだパッチ \((x, x_0)\) 間の「距離」を取得する方法を示している。 \(L\) 層から特徴スタックを抽出し、層 \(l\) について \(\hat{\mathcal F}(x)^l, \hat{\mathcal F}(x_0)^l\in \mathbb R^{H_l×W_l×C_l}\) と指定するチャネル次元で正規化する。各層について、各チャネルの活性度をベクトル \(w^l\in \mathbb R^{C_l}\) でスケーリングし、\(l_2\) 距離を計算する。最後に、空間全体で平均し、チャネル次元全体で合計する。すべての層で \(w_l = 1\) を使用すると、これはコサイン距離を計算することと同等であることに注意。 \[ d(x,x_0)=\sum_l \frac{1}{H_lW_l}\sum_{h,w}||w_l^T\odot(\hat{\mathcal F}(x)_{hw}^l-\hat{\mathcal F}(x_0)_{hw}^l)||_2^2 \tag{1} \] ここで\(\odot\)はチャネル間の乗算を表す。
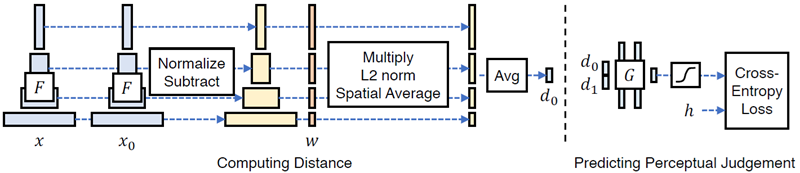
図3: ネットワークからの距離計算 (左) ネットワーク \(\mathcal F\) を用いて2つのパッチ \(x, x_0\) 間の距離 \(d_0\) を計算するために、まず深層埋め込みを計算し、チャネル次元における活性化を正規化し、各チャネルをベクトル \(w\) でスケーリングし、\(l_2\) 距離を求める。次に、空間次元全体と全層にわたって平均化する。(右) 小規模ネットワーク \(\mathcal G\) を、距離ペア \((d_0,d_1)\) から知覚判断 h を予測するように学習させる。
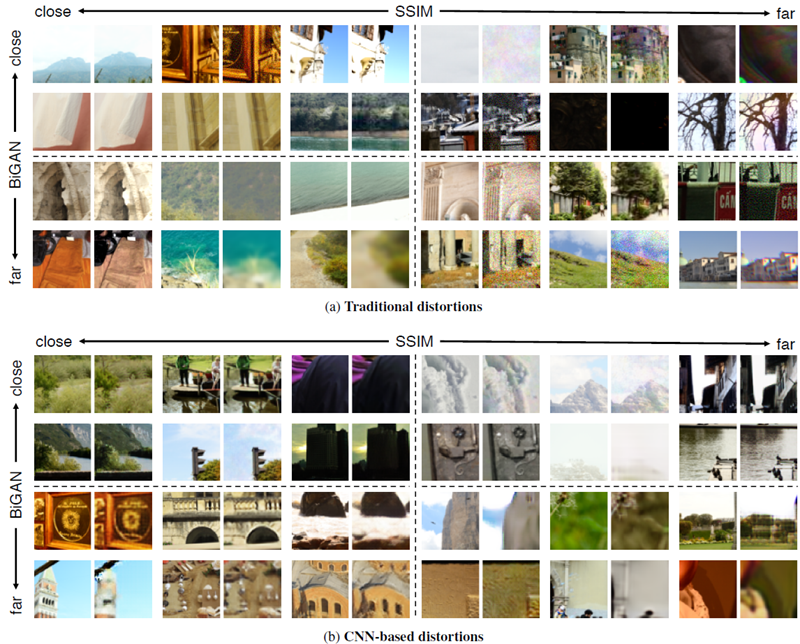
図4:歪みに関する定性的な比較。SSIM [53] 指標とBiGANネットワーク [12] を用いて、(a) 従来の歪みと (b) CNNベースの歪みの定性的な比較を示している。パッチが近い、または遠いという点で両者が一致する例と、指標が一致しない例を示している。主な違いは、深層埋め込みの方がぼかしに対して敏感であるように見えることである。追加の例については付録を参照。
データのトレーニング
知覚的判断を使用してトレーニングするいくつかの異なる方法を検討する。これらの変種は、線形、チューン、スクラッチと呼ばれる。線形構成の場合、事前トレーニング済みのネットワークの重み \(\mathcal F\) を固定し、その上に線形重み \(w\) を学習する。これは、既存の特徴空間内のいくつかのパラメーターを「キャリブレーション」して、人間の知覚により一致するようにする。たとえば、VGG ネットワークの場合、これは 1472 個のパラメーターの学習で構成される。チューン構成では、事前トレーニング済みの分類モデルから初期化し、ネットワーク \(\mathcal F\) のすべての重みを微調整できるようにする。最後に、スクラッチ モデルでは、ネットワークをランダムなガウス重みから初期化し、完全に我々の判断でトレーニングする。全体として、これらを提案する学習知覚画像パッチ類似度 (LPIPS) メトリックの変種と呼ぶ。
図3(右)に、ネットワークを学習するための損失関数を示す。2つの距離 \((d_0, d_1)\) が与えられた場合、その上に小さなネットワーク \(\mathcal G\) を学習させ、スコア \(\hat{h}\in (0,1)\) にマッピングする。このアーキテクチャでは、2つの32チャネルFC-ReLU層、続いて1チャネルFC層とシグモイド層を使用する。最終的な損失関数は式2に示す。 \[ \mathcal L(x,x_0,x_1,h)=-h\log\mathcal G(d(x,x_0),d(x,x_1))-(1-h)\log(1-\mathcal G(d(x,x_0),d(x,x_1))) \tag{2} \]
予備実験では、パッチペア \(d(x, x_0)\) と \(d(x, x_1)\) の間に一定のマージンを強制するランキング損失も試した。その結果、すべてのケースで同じマージンを強制するのではなく、学習済みネットワークを使用する方が効果的であることがわかった。
検証セットの結果を図 5 に示す。まず、メトリクスとネットワークがどれだけ適切に機能するかを評価する。すべての検証セットには、各トリプレットに対して 5 つのペアワイズ判断が含まれている。これは本質的にノイズの多いプロセスであるため、すべての判断に対するアルゴリズムの一致を計算する。たとえば、\(x_0\) の好みが 4つあり、\(x_1\) の好みが1つある場合、より人気のある選択肢である \(x_0\) を予測するアルゴリズムは 80% の評価を得る。特定の例が、一方向に \(p\) 人の人間の割合でスコア付けされ、他方向に \(1-p\) の割合でスコア付けされる場合、オラクル(神託)に対する理論上の最大値は \(\max(p, 1-p)\) である。ただし、人間のパフォーマンスは低くなる。\(p\) がすべての人間の経験的分布を完全に代表する場合、人間は期待値で \(p^2 + (1-p)^2\) のスコアを達成する。
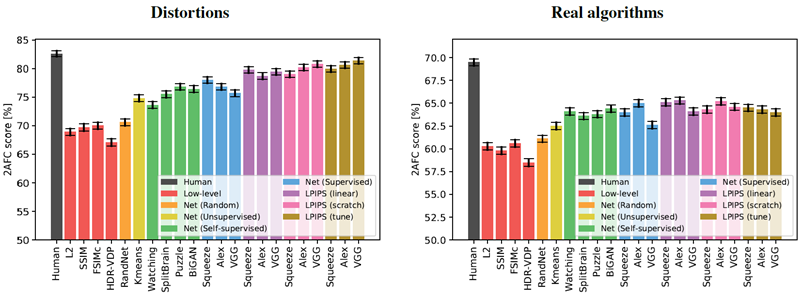
図5:定量的な比較。テストセットにおける指標間の定量的な比較を示す。(左)従来の歪みとCNNベースの歪みを平均した結果。(右)4つの実際のアルゴリズムセットを平均した結果。
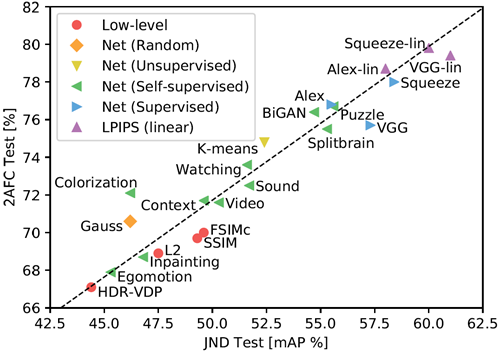
図6:相関知覚テスト。教師なし学習[24]、自己教師学習[1, 41, 11, 52, 58, 38, 40, 37, 12, 59]、教師あり学習[25, 48, 18]、そして我々が提案する知覚学習指標(LPIPS)を含む、様々な手法におけるパフォーマンスを示す。スコアは、我々の知覚テストである2AFCとJNDのスコアであり、従来の歪みとCNNベースの歪みの平均値である。
低レベルメトリクスと分類ネットワークのパフォーマンスはどの程度か?
図 5 は、さまざまな低レベルメトリクス (赤で表示) とディープ ネットワーク、および人間の限界 (黒で表示) のパフォーマンスを示している。スコアは、図 5(a) の 2 つの歪みテスト セット (従来型 + CNN ベース) と、図 5(b) の 4 つの実際のアルゴリズム ベンチマーク (超解像度、フレーム補間、ビデオのぼかし除去、カラー化) にわたって平均されている。付録の表5 は、各テスト セット内のスコアを示している。6 つのテスト セットすべてを平均すると、人間は 73:9% の一貫性がある。興味深いことに、教師ありネットワークは、モデルサイズ (SqueezeNet (2.8 MB)、AlexNet (9.1 MB)、VGG (58.9 MB) (畳み込み層のみカウント)) が異なる場合でも、68.6%、68.9%、67.0% と、ほぼ同じレベルでパフォーマンスを発揮する。図7は、TID2013 [42]データセットのスコアを計算した図である。全てのスケールとレイヤーを平均化し、追加のキャリブレーションを行わない場合でも、AlexNet [25]アーキテクチャは最高の指標であるFSIMc [57]に近いスコアを示している。我々の従来の摂動法では、FSIMc指標は61.4%を達成し、\(l_2\)の59.9%に近い値を示した。一方、我々がテストした深層分類ネットワークでは、それぞれ73.3%、70.6%、70.1%を達成した。
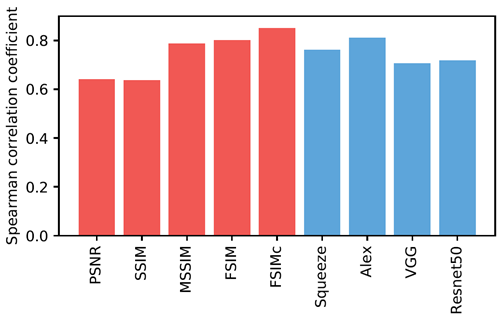
図7:TIDデータセット TID2013データセット[42]における様々な手法のスピアマン相関係数を示す。分類用に学習された深層ネットワークは、そのままでも良好なパフォーマンスを示している(青)。
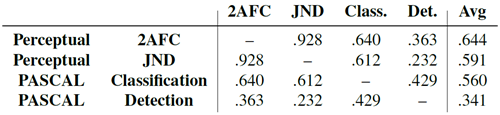
表4:タスク相関。低レベル知覚テストと高レベル意味テストのスコアを、手法間で相関させた。知覚スコアは、従来の歪みセットとCNNベースの歪みセットの平均である。相関スコアは、AlexNetのようなアーキテクチャに基づいて計算された。
知覚ネットワークは分類について学習させる必要があるか?
図5は、様々な教師なしおよび自己教師タスク(緑色で示されている)におけるモデル性能を示している。BiGANを用いた生成モデリング[12]、パズルの解法[37]、クロスチャネル予測[59]、およびビデオからの前景オブジェクトのセグメンテーション[40]である。これらの自己教師タスクは分類ネットワークと同等の性能を示している。これは、広範囲にわたるタスクが、知覚距離にうまく転移する表現を誘導できることを示す。また、黄色で示されているスタックk-means法[24]の性能は、低レベルの指標よりも優れている。ガウス分布から重みを導出したランダムネットワーク(オレンジ色で示されている)では、大きな改善は見られない。これは、ネットワーク構造と、データがより密集している方向にフィルターを向けることを組み合わせることで、知覚判断との相関性が高まることを示している。
表6では、[59]にまとめられた結果と追加の自己教師あり学習法[1, 41, 11, 52, 58, 38]を用いて、知覚タスクがPASCALデータセット[14]の意味タスクとどの程度相関するかを調べている。各タスク(知覚タスクまたは意味タスク)について、異なる手法のパフォーマンススコアをベクトルとして扱い、相関係数を計算した。2AFC歪み選好タスクから分類および検出への相関は、それぞれ.640と.363である。興味深いことに、分類タスクと検出タスクはどちらも「高レベル」の意味タスクであるのに対し、知覚タスクは「低レベル」であるにもかかわらず、この相関は分類タスクと検出タスク間の相関(.429)と似ている。
異なる知覚タスク間でメトリクスは相関するのか?
2AFC歪み選好テストのトレーニングが、別の知覚タスクであるJNDテストと対応するかどうかをテストする。特定のメトリクスでパッチペアを昇順に並べ、CNNベースの歪みの適合率と再現率を計算する。良いメトリクスの場合、互いに近いパッチは同じものと混同される可能性が高くなる。mAP [14]として知られる曲線の下の領域を計算する。2AFC歪み選好テストは、歪みタイプ全体の結果を平均すると、\(JND –\rho= .928\) と高い相関がある。図6は、各知覚テストで異なる方法がどのように機能するかを示している。これは、我々のテストが別のタイプの知覚テストに一般化されることを示しており、人間の判断に関するシグナルを与えてくる。
従来の歪みとCNNベースの歪みの両方で指標を学習できるか?
図5は、それぞれ紫、ピンク、茶色で示されている線形、スクラッチ、チューニング構成を使用した場合のパフォーマンスを示している。従来の歪みとCNNベースの歪み(図5(a))で検証すると、改善が見られる。ネットワークを完全にチューニングすることを許可すると(茶色)、単純に線形重みを学習する(紫)またはゼロから学習する(ピンク)よりも高いパフォーマンスが得られる。高容量ネットワークVGGは、低容量ネットワークSqueezeNetとAlexNetも実行する。学習とテストの分布が同じであるため、これらの結果は驚くべきものではない。しかし、ネットワークが知覚判断から学習できることは実証されている。
従来の歪みや CNN ベースの歪みのトレーニングは、実際のシナリオに転移できるか?
我々は、図 5(b) に示すように、パフォーマンスが実際のアルゴリズムにどのように一般化されるかにもっと興味がある。Squeezenet、AlexNet、および VGG アーキテクチャは、それぞれ 64.0%、65.0%、および 62.6% から始まる。線形分類器 (紫) を学習すると、すべてのネットワークのパフォーマンスが向上する。3 つのネットワークと 4 つの実際のアルゴリズム タスク全体で、12 のスコアのうち 11 が向上した。これは、データを使用して既存の表現でアクティベーションを「キャリブレーション」することが、パフォーマンスをわずかに向上させる安全な方法であることを示している (それぞれ 1.1%、0.3%、および 1.5%)。ネットワークを最初からトレーニングすると (ピンク)、線形キャリブレーションよりも AlexNet のパフォーマンスがわずかに低下し、VGG のパフォーマンスがわずかに高くなる。ただし、これらは依然として低レベルのメトリックよりも優れている。これは、我々が表現した歪みが、実際のアルゴリズムを判断するテスト時のタスクに投影されることを示している。
興味深いことに、事前学習済みのネットワークから始めて全体をチューニングすると、転移性能が低下する。これは興味深い否定的な結果である。なぜなら、低レベルの知覚タスクを直接学習しても、高レベルのタスク向けに学習された表現を転移した場合と同等の性能が必ずしも得られるわけではないからである。
深層メトリクスと低レベルメトリクスの相違点はどこにあるのか?
図4は、深層学習手法であるBiGAN [12]と、従来の知覚表現手法であるSSIM [53]について、従来の歪みとCNNベースの歪みを定性的に比較したものである。BiGANが遠くにあると認識する一方でSSIMが近くにあると認識するパッチペアには、一般的に多少のぼやけが含まれている。逆の場合、BiGANは相関ノイズパターンをSSIMよりも小さな歪みとして認識する傾向がある。
我々の研究結果は、難しい視覚予測とモデリングのタスクを解くように訓練されたネットワークが、知覚判断とよく相関する世界の表現を学習することを示している。 表現学習の文献でも最近、似たような話が出ている。自己教師ありおよび教師なしの目的で訓練されたネットワークが、意味タスクでも効果的な表現を学習することになる [11]。 興味深いことに、神経科学の最近の研究結果もほぼ同じことを指摘している。コンピューター ビジョンのタスクで訓練された表現は、マカク視覚皮質の神経活動の効果的なモデルにもなる [56]。 さらに (そして大まかに言えば)、コンピューター ビジョンのタスクで表現が強力であればあるほど、皮質活動のモデルとしても強力になる。我々の論文でも同様の発見がある。表 4 に示すように、分類と検出で特徴セットが強力であればあるほど、知覚的類似性判断のモデルとしても強力になる。 これらの結果を合わせると、良い特徴はよい機能である(? a good feature is a good feature)ことを示唆している。意味的タスクに優れた特徴は、自己教師ありタスクおよび教師なしタスクにも優れており、人間の知覚行動とマカクザルの神経活動の両方の優れたモデルを提供する。この最後の点は、視覚認知における「合理的分析」の説明[4]と一致しており、生物学的知覚の特異性は、合理的なエージェントが自然なタスクを解決しようとする結果として生じることを示唆している。この説明がどの程度真実であるかをさらに精緻化することは、今後の研究における重要な課題である。
本研究は、Berkeley Deep Drive、NSF IIS-1633310からの助成金、およびNVIDIA Corp.からのハードウェア提供によって一部支援されました。有益な議論をしてくださったBerkeley AI Research LabおよびAdobe Creative Intelligence Labのメンバーに感謝します。また、データ準備にご協力いただいたRadu Timofte氏、ZhaowenWang氏、MichaelWaechter氏、Simon Niklaus氏、Sergio Guadarrama氏にも感謝いたします。RZはAdobe Research Fellowshipの支援を受けており、本研究の多くはRZがAdobe Researchでインターンとして勤務していた間に行われました。
完全な定量的詳細は付録 A に記載している。また、トレーニングの詳細については付録 B で説明する。
表 5 では、すべての検証セットと考慮されたメトリック (低レベルのメトリックを含む)、およびランダム、教師なし、自己教師、教師あり、知覚学習ネットワークにわたる完全な定量的結果を示している。
図8、9、10は、個々の検証セットにおけるパフォーマンスを示している。図8は従来の歪みとCNNベースの歪みを示しており、図9、10は実際のアルゴリズムを個別に適用した結果を示している。
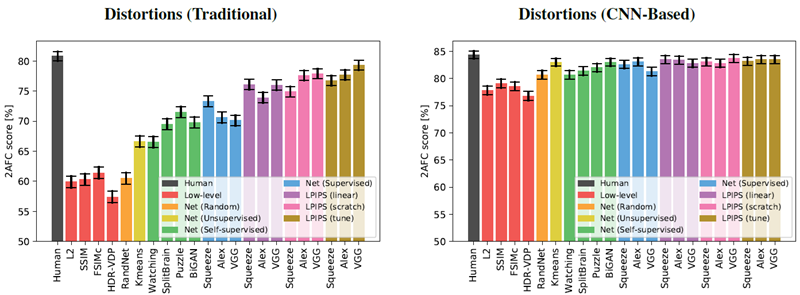
図8: 個々の結果(左)従来の歪み(右)CNNベースの歪み
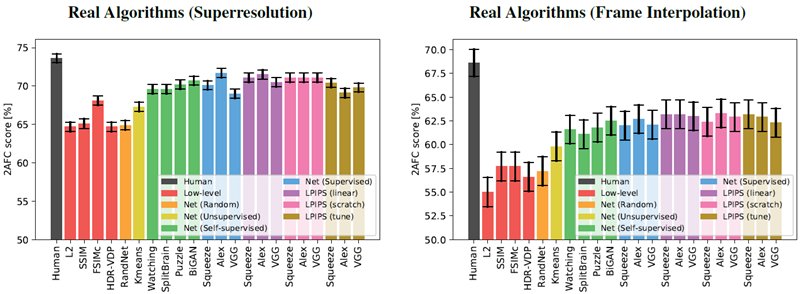
図9: 個々の結果(左)超解像(右)フレーム補間
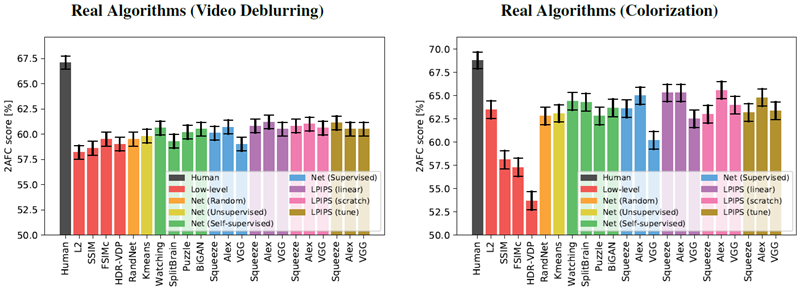
図10: 個別の結果(左)ビデオのぼかし除去(右)カラー化
線形較正ネットワーク
Alex モデル上で線形重みを学習すると、実際のアルゴリズムのテスト セットで最先端の結果が達成される。線形モデルは各チャネル上に学習済みの線形層を持つが、すぐに使用できるバージョンでは各チャネルに均等に重みが付けられる。図11a に、Alex –frozen モデルの学習済みの重みを示す。conv1-5 層には、それぞれ 64、192、384、256、256 チャネルが含まれており、重みの合計は 1152 個である。各層 conv1-5 では、重みのそれぞれ 79.7%、71.4%、56.8%、46.5%、27.7% が 0 である。つまり、conv1 および conv2 ユニットの大部分は無視され、conv5 ユニットのほぼすべてが使用されている。全体として、ユニットの約半分が無視される。コサイン距離を取ることは、すべての重みを 1 に設定することと同じである (図 11b)。
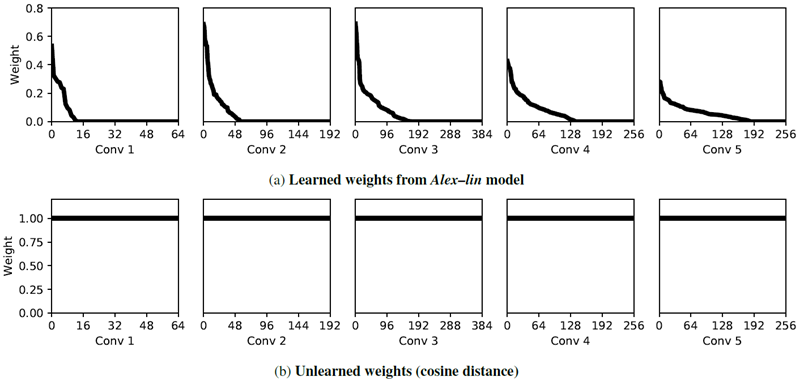
図11:レイヤーごとに学習された線形重み。(上) Alex – 凍結モデルの各レイヤーから学習された重みを示す。これは図3の \(w\) 項に相当する。各サブプロットは、各レイヤーのチャネル重みを降順に並べたものである。\(x\) 軸はチャネル番号、\(y\) 軸は重みを示す。画像パッチは負の距離を持つべきではないため、重みは非負に制限される。(下) 学習されていない重みは、各レイヤーの各チャネルに重み \(1\) を適用し、コサイン距離を計算する。
歪みに関するモデル学習のためのデータ量
ここでは、歪みに基づいて学習したネットワークのモデル学習について、いくつか追加の詳細を示す。初期学習率 \(10-{-4}\)、線形減衰を使った 5 エポック、バッチサイズ 50 で 5 エポック学習する。各学習パッチペアは 2 回判定され、判定結果はグループ化される。たとえば、2 人の判定者が分割された場合、分類ターゲット (図3 の h) は 0.5 に設定される。特定の特徴における距離が大きくなっても、2 つのパッチが距離メトリックで近づくことはあってはならないため、線形層 \(w\) に非負の重みを適用する。これは、反復ごとに重みを制約セットに投影することによって行われる。言い換えれば、負の重みがないかチェックし、それらを 0 に強制する。このプロジェクトは PyTorch [39] を使用して実装された。
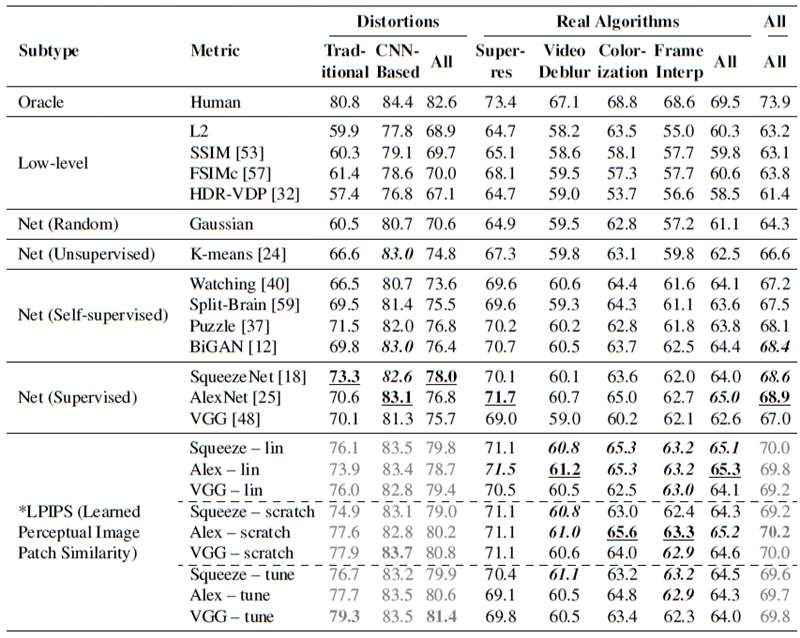
表5:結果。様々な手法とテストセットにおける2AFCスコア(高いほど良い)を示している。太字で下線が引かれた値は最も高いパフォーマンスを示している。太字で斜体の値は、最高値から0.5%以内である。*LPIPS指標は、同じ従来の歪みとCNNベースの歪みを用いてトレーニングされているため、同じ歪みタイプ、さらには未知のテスト画像であっても、他の手法と比較して優位性がある。これらの値はグレー値で示されている。列ごとに最も良いグレー値も太字で示されている。